PageIndex Agent工作流
经 AI Skill Hub 精选评估,PageIndex Agent工作流 获评「强烈推荐」。在 GitHub 上收获超过 31.2k 颗 Star,这款Agent工作流在功能完整性、社区活跃度和易用性方面表现出色,AI 评分 8.2 分,适合有一定技术背景的用户使用。
PageIndex Agent工作流 工作流的设计遵循"最小配置,最大复用"原则:核心逻辑已经封装好,用户只需配置自己的 API Key 和业务参数即可快速上手。工作流内置错误处理和重试机制,在网络波动或 API 限速等情况下仍能稳定运行,适合作为生产环境的自动化基础设施。
在实际部署时,建议先在测试环境中运行 3-5 次,验证各个环节的输出结果符合预期,再部署到生产环境。AI Skill Hub 评分 8.2 分,是同类 Agent 工作流中的精选推荐。
PageIndex Agent工作流 是一套完整的 AI Agent 自动化工作流方案。通过可视化的节点编排,将复杂的多步骤任务拆解为清晰的自动化流程,实现全程无人值守的智能处理。支持与数百种外部服务和 API 无缝集成,适合构建数据处理管线、业务自动化和 AI 辅助决策系统。
PageIndex Agent工作流 是一套完整的 AI Agent 自动化工作流方案。通过可视化的节点编排,将复杂的多步骤任务拆解为清晰的自动化流程,实现全程无人值守的智能处理。支持与数百种外部服务和 API 无缝集成,适合构建数据处理管线、业务自动化和 AI 辅助决策系统。
- 可视化 Agent 工作流编排,无需编写复杂代码
- 支持多步骤自动化任务链,实现全流程无人值守
- 与外部 API、数据库和第三方服务无缝集成
- 内置错误处理与自动重试机制,保障稳定运行
- 提供可复用的自动化模板,快速在同类场景部署
- 自动化日常重复性工作,将精力集中于创造性任务
- 构建数据采集 → 处理 → 输出的完整自动化管线
- 实现跨平台、跨系统的数据流转和业务协同
# 方式一:pip 安装(推荐)
pip install pageindex
# 方式二:虚拟环境安装(推荐生产环境)
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install pageindex
# 方式三:从源码安装(获取最新功能)
git clone https://github.com/VectifyAI/PageIndex
cd PageIndex
pip install -e .
# 验证安装
python -c "import pageindex; print('安装成功')"
- 访问 GitHub 仓库获取工作流文件
- 在对应平台(Dify / Flowise / Make 等)中找到「导入工作流」功能
- 上传工作流文件
- 按照提示配置必要的环境变量和 API Key
- 运行测试确认流程正常后投入使用
# 命令行使用
pageindex --help
# 基本用法
pageindex input_file -o output_file
# Python 代码中调用
import pageindex
# 示例
result = pageindex.process("input")
print(result)
# pageindex 配置文件示例(config.yml) app: name: "pageindex" debug: false log_level: "INFO" # 运行时指定配置文件 pageindex --config config.yml # 或通过环境变量配置 export PAGEINDEX_API_KEY="your-key" export PAGEINDEX_OUTPUT_DIR="./output"
简介
<br/> <br/>
<p align="center"> <a href="https://trendshift.io/repositories/14736" target="_blank"><img src="https://trendshift.io/api/badge/repositories/14736" alt="VectifyAI%2FPageIndex | Trendshift" style="width: 250px; height: 55px;" width="250" height="55"/></a> </p>
📑 Introduction to PageIndex
Are you frustrated with vector database retrieval accuracy for long professional documents? Traditional vector-based RAG relies on semantic similarity rather than true relevance. But similarity ≠ relevance — what we truly need in retrieval is relevance, and that requires reasoning. When working with professional documents that demand domain expertise and multi-step reasoning, similarity search often falls short.
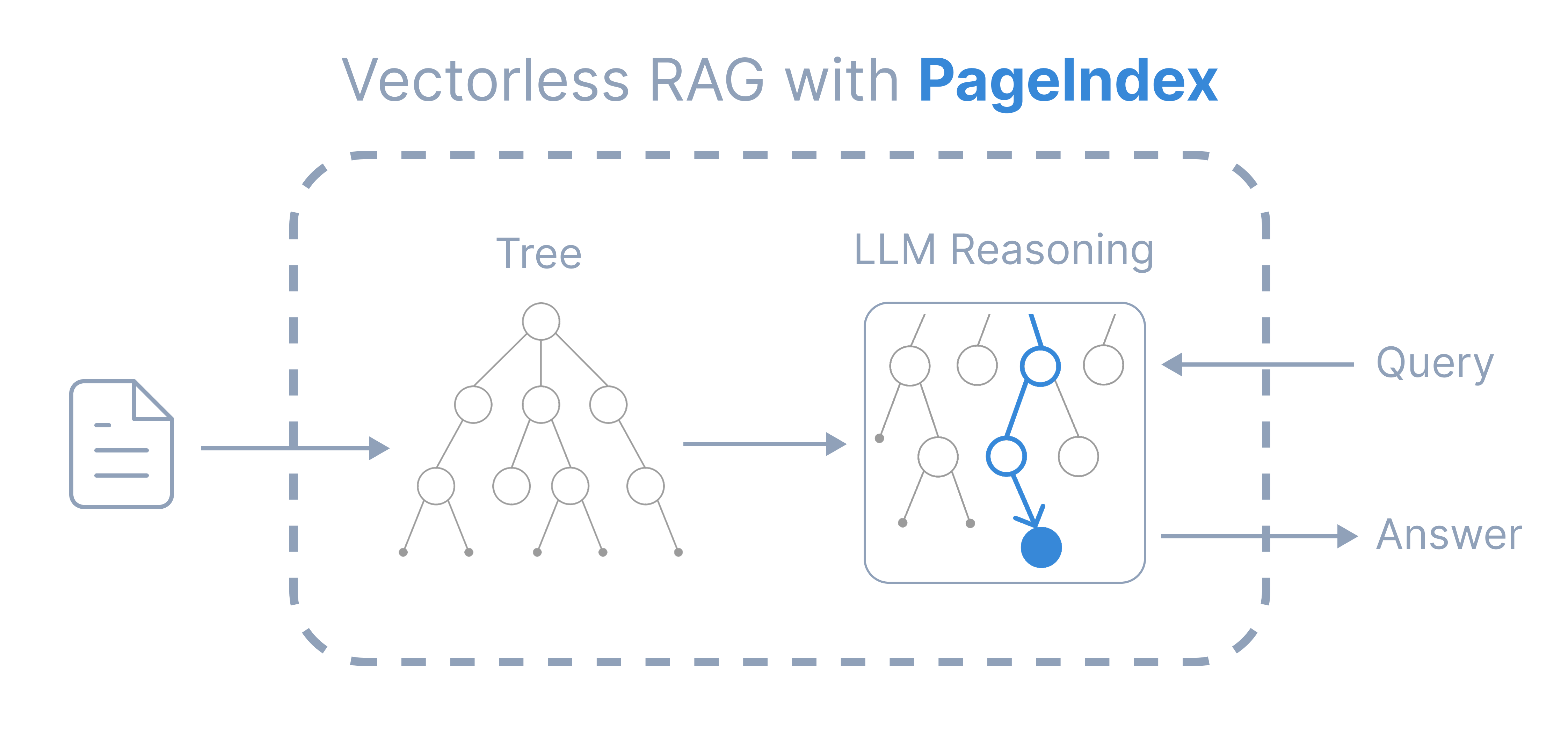
Inspired by AlphaGo, we propose PageIndex — a vectorless, reasoning-based RAG system that builds a hierarchical tree index from long documents and uses LLMs to reason over that index for agentic, context-aware retrieval. It simulates how human experts navigate and extract knowledge from complex documents through tree search, enabling LLMs to think and reason their way to the most relevant document sections. PageIndex performs retrieval in two steps:
- Generate a “Table-of-Contents” tree structure index of documents
- Perform reasoning-based retrieval through tree search
🎯 Core Features
Compared to traditional vector-based RAG, PageIndex features: - No Vector DB: Uses document structure and LLM reasoning for retrieval, instead of vector similarity search. - No Chunking: Documents are organized into natural sections, not artificial chunks. - Better Explainability and Traceability: Retrieval is based on reasoning, traceable and interpretable, with page and section references. No more opaque, approximate vector search (“vibe retrieval”). - Context-Aware Retrieval: Retrieval depends on your full context (e.g., conversation history and domain knowledge), and easily incorporates new context. - Human-like Retrieval: Simulates how human experts navigate and extract knowledge from complex documents.
PageIndex powers a reasoning-based RAG system that achieved state-of-the-art 98.7% accuracy on FinanceBench, demonstrating superior performance over vector-based RAG solutions in professional document analysis. See our blog post for details.
1. Install dependencies
pip3 install --upgrade -r requirements.txtInstall optional dependency
pip3 install openai-agents
🛠️ Deployment Options
- Self-host — run locally with this open-source repo (using standard PDF parsing).
- Cloud Service — production-grade pipeline with enhanced OCR, tree building, and retrieval for best results. Try instantly with our Chat Platform, or integrate via MCP or API.
- Enterprise — private or on-prem deployment. Contact us or book a demo for more details.
⚙️ Package Usage
Note: This package uses standard PDF parsing. For use cases with complex PDFs, our cloud service (via MCP and API) offers enhanced OCR, tree building, and retrieval.
You can follow these steps to generate a PageIndex tree from a PDF document.
Agentic Vectorless RAG: An Example
For a simple, end-to-end agentic vectorless RAG example using self-hosted PageIndex (with OpenAI Agents SDK), see examples/agentic_vectorless_rag_demo.py.
```bash
Run the demo
python3 examples/agentic_vectorless_rag_demo.py ```
---
2. Set your LLM API key
Create a .env file in the root directory with your LLM API key. Multi-LLM is supported via LiteLLM:
OPENAI_API_KEY=your_openai_key_here📈 Case Study: PageIndex Leads Finance QA Benchmark
Mafin 2.5 is a reasoning-based RAG system for financial document analysis, powered by PageIndex. It achieved a state-of-the-art 98.7% accuracy on the FinanceBench benchmark, significantly outperforming traditional vector-based RAG systems.
PageIndex's hierarchical indexing and reasoning-driven retrieval enable precise navigation and extraction of relevant context from complex financial reports, such as SEC filings and earnings disclosures.
Explore the full benchmark results and our blog post for detailed comparisons and performance metrics.
---
创新性强,以推理替代向量化的RAG思路值得关注。社区热度高(31k星),架构设计先进,适合前沿应用探索。文档完整度需验证。
- 需要让 Claude / Cursor 操作本地工具的 AI 工程师
- 构建多智能体协作系统的 Agent 开发者
- 构建企业知识库 / RAG 检索应用的团队
- 需要从图片、PDF 提取文字的文档自动化场景
- 配置 MCP 服务器时建议使用 stdio 传输 + JSON-RPC,避免暴露公网
- 分块大小建议 256-512 tokens,向量库优选 pgvector 或 Qdrant
- Agent 任务先做 dry-run 验证工具调用链,再开启自主执行
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- MCP 配置路径拼错或权限不足,重启 Claude Desktop 才生效
- embedding 模型与查询模型不一致导致检索失效
- Python 依赖冲突:建议用 venv / uv 隔离环境
- 云端托管:可放在 Vercel / Railway / Fly.io 等 PaaS 平台
- 可视化 Agent 工作流编排,无需编写复杂代码
- 支持多步骤自动化任务链,实现全流程无人值守
- 与外部 API、数据库和第三方服务无缝集成
- 内置错误处理与自动重试机制,保障稳定运行
- 提供可复用的自动化模板,快速在同类场景部署
- 需要让 Claude / Cursor 操作本地工具的 AI 工程师
- 构建多智能体协作系统的 Agent 开发者
- 构建企业知识库 / RAG 检索应用的团队
- 需要从图片、PDF 提取文字的文档自动化场景
- 配置 MCP 服务器时建议使用 stdio 传输 + JSON-RPC,避免暴露公网
- 分块大小建议 256-512 tokens,向量库优选 pgvector 或 Qdrant
- Agent 任务先做 dry-run 验证工具调用链,再开启自主执行
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- MCP 配置路径拼错或权限不足,重启 Claude Desktop 才生效
- embedding 模型与查询模型不一致导致检索失效
- Python 依赖冲突:建议用 venv / uv 隔离环境
- 自动化日常重复性工作,将精力集中于创造性任务
- 构建数据采集 → 处理 → 输出的完整自动化管线
- 实现跨平台、跨系统的数据流转和业务协同
- +GitHub 31.2k Star,社区高度认可
- +MIT 协议,可免费商用
- +大幅减少重复性人工操作
- +可视化流程,清晰直观
- +可扩展性强,支持复杂场景
- −初始配置和调试需投入一定时间
- −强依赖外部服务的稳定性
- −复杂场景需具备一定技术基础
AI Skill Hub 为第三方内容聚合平台,本页面信息基于公开数据整理,不对工具功能和质量作任何法律背书。
建议在沙箱或测试环境中充分验证后,再部署至生产环境,并做好必要的安全评估。
✅ MIT 协议 — 最宽松的开源协议之一,可自由商用、修改、分发,仅需保留版权声明。
AI Skill Hub 点评:PageIndex Agent工作流 的核心功能完整,质量优秀。对于自动化工程师和运维人员来说,这是一个值得纳入个人工具库的选择。建议先在非生产环境试用,再逐步推广。
| 原始名称 | PageIndex |
| 原始描述 | 开源AI工作流:📑 PageIndex: Document Index for Vectorless, Reasoning-based RAG。⭐31.2k · Python |
| Topics | RAG文档索引推理引擎AI工作流Agent框架 |
| GitHub | https://github.com/VectifyAI/PageIndex |
| License | MIT |
| 语言 | Python |
收录时间:2026-05-14 · 更新时间:2026-05-16 · License:MIT · AI Skill Hub 不对第三方内容的准确性作法律背书。
🤖 交给 Agent 安装 · PageIndex Agent工作流
选择 Agent 类型,复制安装指令后粘贴到对应客户端