
vmlx MCP工具
经 AI Skill Hub 精选评估,vmlx MCP工具 获评「强烈推荐」。这款AI工具在功能完整性、社区活跃度和易用性方面表现出色,AI 评分 8.2 分,适合有一定技术背景的用户使用。
**为什么要使用开源工具而非商业 SaaS?**
对于个人开发者和有隐私需求的用户,本地部署的开源工具意味着数据不离本机,不受第三方服务商的数据政策约束。同时,开源工具通常没有使用次数限制和月度费用,一次安装即可长期使用,对于高频使用场景的总拥有成本(TCO)远低于订阅制商业工具。
**安装与环境准备**
vmlx MCP工具 依赖 Python 运行环境。建议通过 pyenv(Python)或 nvm(Node.js)管理 Python 版本,避免全局环境污染。对于新手用户,推荐先创建虚拟环境(python -m venv venv && source venv/bin/activate),再安装依赖,这样即使出现问题也可以随时删除虚拟环境重新开始,不影响系统稳定性。
**社区与维护**
GitHub Issue 和 Discussion 是获取帮助的最快渠道。在提问前建议先检查 Closed Issues(已关闭的问题),大多数常见问题都已有解答。遇到 Bug 时,提供 pip list 的输出、完整错误堆栈和最小可复现示例,能显著提高开发者响应速度。AI Skill Hub 将持续追踪 vmlx MCP工具 的版本更新,及时通知重要功能变化。
vmlx MCP工具 是一款基于 Python 开发的开源工具,专注于 模型压缩、KV缓存优化、MLX框架 等核心功能。作为 GitHub 开源项目,它拥有活跃的社区支持和持续的版本迭代,代码完全透明可审计,支持本地部署以保护数据隐私。无论是个人使用还是集成到企业工作流,都能提供稳定可靠的解决方案。
vmlx MCP工具 是一款基于 Python 开发的开源工具,专注于 模型压缩、KV缓存优化、MLX框架 等核心功能。作为 GitHub 开源项目,它拥有活跃的社区支持和持续的版本迭代,代码完全透明可审计,支持本地部署以保护数据隐私。无论是个人使用还是集成到企业工作流,都能提供稳定可靠的解决方案。
- 开源免费,支持本地部署,数据完全自主可控
- 活跃的 GitHub 开源社区,持续迭代更新
- 提供详细文档和使用示例,新手友好
- 支持自定义配置,灵活适配不同使用环境
- 可作为基础组件集成进现有技术栈或进行二次开发
- 本地部署运行,保护数据隐私,满足合规要求
- 自定义集成到现有系统,扩展技术栈能力
- 作为开源基础组件进行商业化二次开发
# 方式一:pip 安装(推荐)
pip install vmlx
# 方式二:虚拟环境安装(推荐生产环境)
python -m venv .venv
source .venv/bin/activate # Windows: .venv\Scripts\activate
pip install vmlx
# 方式三:从源码安装(获取最新功能)
git clone https://github.com/jjang-ai/vmlx
cd vmlx
pip install -e .
# 验证安装
python -c "import vmlx; print('安装成功')"
- 访问 GitHub 仓库页面
- 按照 README 文档完成依赖安装
- 根据系统环境完成初始化配置
- 参考官方示例或文档开始使用
- 遇到问题可在 GitHub Issues 中查找解答
# 命令行使用
vmlx --help
# 基本用法
vmlx input_file -o output_file
# Python 代码中调用
import vmlx
# 示例
result = vmlx.process("input")
print(result)
# vmlx 配置文件示例(config.yml) app: name: "vmlx" debug: false log_level: "INFO" # 运行时指定配置文件 vmlx --config config.yml # 或通过环境变量配置 export VMLX_API_KEY="your-key" export VMLX_OUTPUT_DIR="./output"
简介
<p align="center"> <picture> <source media="(prefers-color-scheme: dark)" srcset="https://raw.githubusercontent.com/jjang-ai/vmlx/main/assets/logo-wide-dark.png"> <source media="(prefers-color-scheme: light)" srcset="https://raw.githubusercontent.com/jjang-ai/vmlx/main/assets/logo-wide-light.png"> <img alt="vMLX" src="https://raw.githubusercontent.com/jjang-ai/vmlx/main/assets/logo-wide-light.png" width="400"> </picture> </p>
MLX Inference Server for Apple Silicon
<p align="center"> Self-hosted inference server for LLMs, VLMs, and image generation on Apple Silicon.<br> OpenAI + Anthropic + Ollama compatible HTTP API. Self-hosted; no third-party API keys required.<br> Native MTP artifact detection and family-specific cache policy gates keep speculative/cache settings explicit and model-safe. </p>
<p align="center"> <em>Looking for a native Swift macOS app or Swift inference engine? See <a href="https://osaurus.ai">osaurus.ai</a>.</em> </p>
<p align="center"> <a href="https://pypi.org/project/vmlx/"><img src="https://img.shields.io/pypi/v/vmlx?color=%234B8BBE&label=PyPI&logo=python&logoColor=white" alt="PyPI" /></a> <a href="https://github.com/jjang-ai/vmlx/blob/main/LICENSE"><img src="https://img.shields.io/badge/License-Apache_2.0-green?logo=apache" alt="License" /></a> <a href="https://github.com/jjang-ai/vmlx"><img src="https://img.shields.io/github/stars/jjang-ai/vmlx?style=social" alt="Stars" /></a> <img src="https://img.shields.io/badge/Apple_Silicon-M1%2FM2%2FM3%2FM4-black?logo=apple" alt="Apple Silicon" /> <img src="https://img.shields.io/badge/Python-3.10+-3776AB?logo=python&logoColor=white" alt="Python" /> <img src="https://img.shields.io/badge/Electron-28-47848F?logo=electron&logoColor=white" alt="Electron" /> <a href="https://ko-fi.com/jangml"><img src="https://img.shields.io/badge/Support-Ko--fi-FF5E5B?logo=ko-fi&logoColor=white" alt="Ko-fi" /></a> </p>
<p align="center"> <a href="#quickstart">Quickstart</a> • <a href="#model-support">Models</a> • <a href="#features">Features</a> • <a href="#image-generation--editing">Image Gen</a> • <a href="#api-reference">API</a> • <a href="#desktop-app">Desktop App</a> • <a href="#advanced-quantization">JANG</a> • <a href="#cli-commands">CLI</a> • <a href="#configuration">Config</a> • <a href="#contributing">Contributing</a> • <a href="#한국어-korean">한국어</a> </p>
---
JANG 2-bit destroys MLX 4-bit on MiniMax M2.5: | Quantization | MMLU (200q) | Size | |---|---|---| | JANG\_2L (2-bit) | 74% | 89 GB | | MLX 4-bit | 26.5% | 120 GB | | MLX 3-bit | 24.5% | 93 GB | | MLX 2-bit | 25% | 68 GB | Adaptive mixed-precision keeps critical layers at higher precision. Scores at jangq.ai. Models at JANGQ-AI.
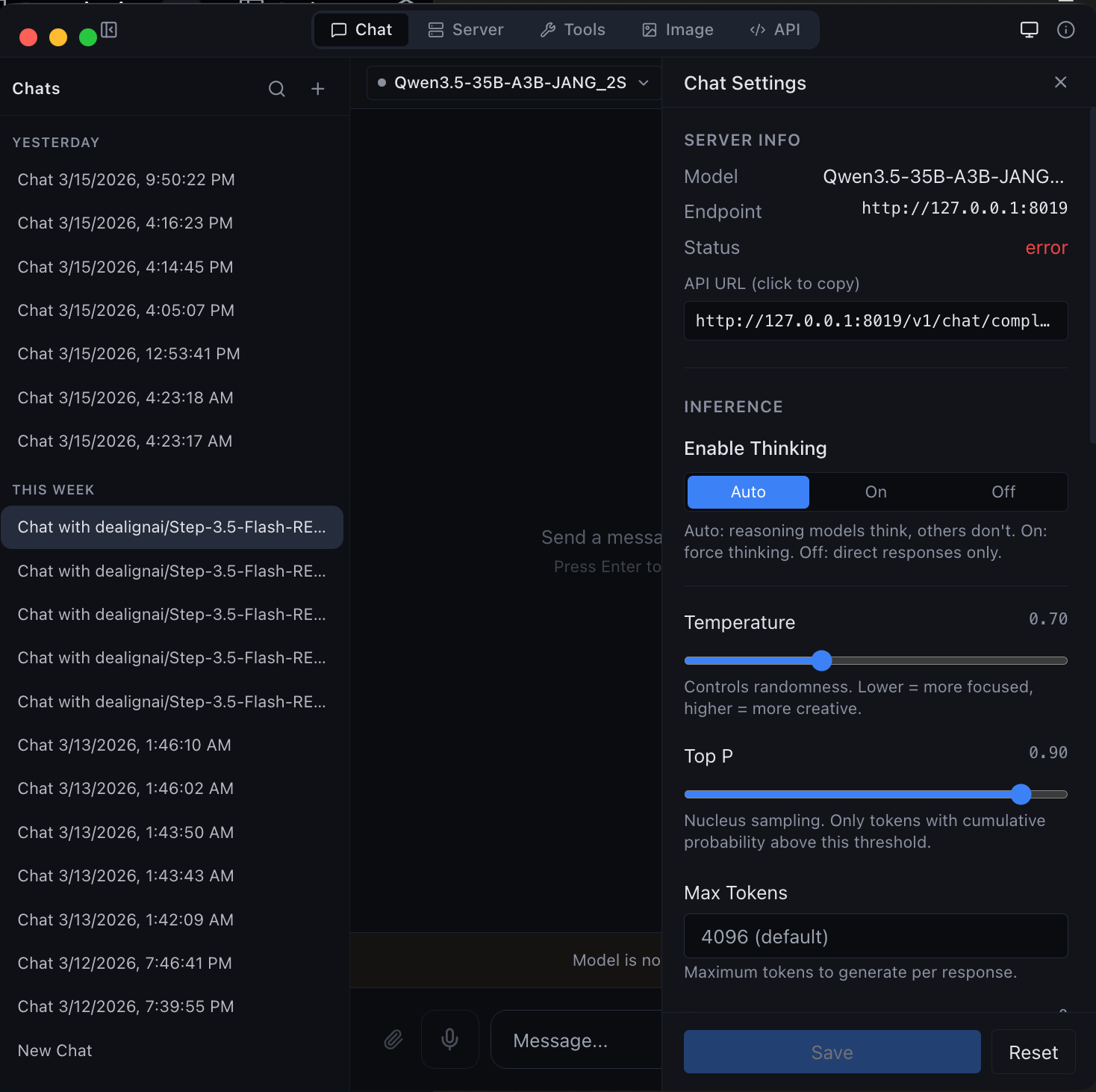 |
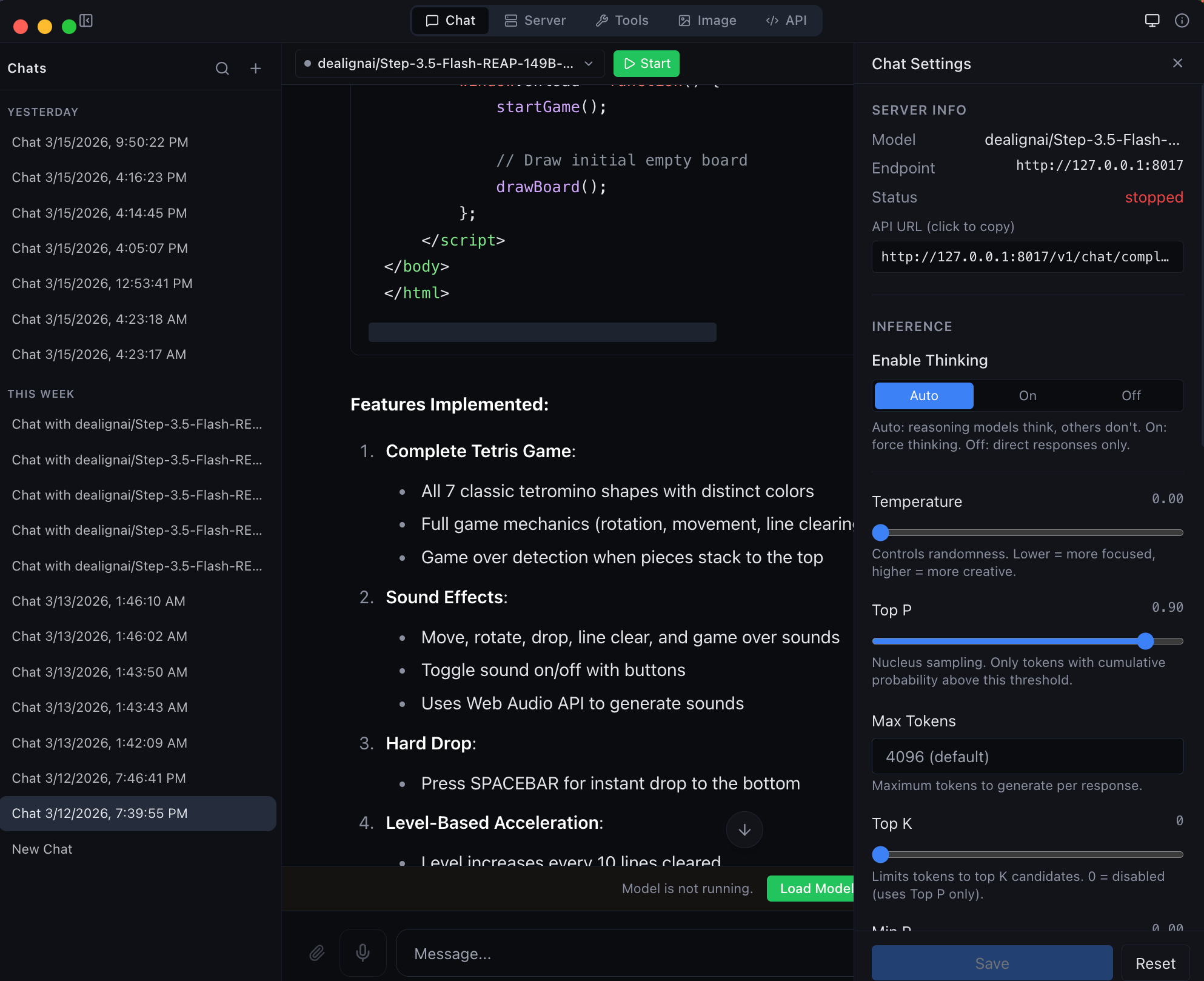 |
| Chat with any MLX model -- thinking mode, streaming, and syntax highlighting | Agentic chat with full coding capabilities -- tool use and structured output |
---
Features
Optional Dependencies
pip install vmlx # Core: text LLMs, VLMs, embeddings, reranking
pip install vmlx[image] # + Image generation (mflux)
pip install vmlx[jang] # + JANG quantization tools
pip install vmlx[dev] # + Development/testing tools
pip install vmlx[image,jang] # Multiple extras---
Install from PyPI
Published on PyPI as vmlx -- install and run in one command:
```bash
Or: pip in a virtual environment
python3 -m venv ~/.vmlx-env && source ~/.vmlx-env/bin/activate pip install vmlx vmlx serve mlx-community/Qwen3-8B-4bit ```
Note: On macOS 14+, barepip installfails with "externally-managed-environment". Useuv,pipx, or a venv.
The vMLX inference server is now running at http://0.0.0.0:8000 with an OpenAI + Anthropic compatible API. Works with any model from mlx-community -- thousands of models ready to go.
Quickstart
curl Examples
Chat completion (streaming)
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"messages": [{"role": "user", "content": "Explain quantum computing in 3 sentences."}],
"stream": true,
"temperature": 0.7
}'Chat completion with thinking mode
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"messages": [{"role": "user", "content": "Solve: what is 23 * 47?"}],
"enable_thinking": true,
"stream": true
}'Tool calling
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"messages": [{"role": "user", "content": "What is the weather in Tokyo?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather for a location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "City name"}
},
"required": ["location"]
}
}
}]
}'Anthropic Messages API
curl http://localhost:8000/v1/messages \
-H "Content-Type: application/json" \
-H "x-api-key: not-needed" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "local",
"max_tokens": 1024,
"messages": [{"role": "user", "content": "Hello!"}]
}'Embeddings
curl http://localhost:8000/v1/embeddings \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"input": "The quick brown fox jumps over the lazy dog"
}'Text-to-speech
curl http://localhost:8000/v1/audio/speech \
-H "Content-Type: application/json" \
-d '{
"model": "kokoro",
"input": "Hello, welcome to vMLX!",
"voice": "af_heart"
}' --output speech.wavSpeech-to-text
curl http://localhost:8000/v1/audio/transcriptions \
-F file=@audio.wav \
-F model=whisperImage generation
curl http://localhost:8000/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"model": "schnell",
"prompt": "A mountain landscape at sunset",
"size": "1024x1024"
}'Reranking
curl http://localhost:8000/v1/rerank \
-H "Content-Type: application/json" \
-d '{
"model": "local",
"query": "What is machine learning?",
"documents": [
"ML is a subset of AI",
"The weather is sunny today",
"Neural networks learn from data"
]
}'Cache stats
curl http://localhost:8000/v1/cache/statsHealth check
curl http://localhost:8000/health---
Guidelines
- Run the full test suite before submitting PRs
- Follow existing code style and patterns
- Include tests for new features
- Update documentation for user-facing changes
---
Recommended: uv (fast, no venv hassle)
brew install uv uv tool install vmlx vmlx serve mlx-community/Qwen3-8B-4bit
Configuration
Server Options
vmlx serve <model> \
--host 0.0.0.0 \ # Bind address (default: 0.0.0.0)
--port 8000 \ # Port (default: 8000)
--api-key sk-your-key \ # Optional API key authentication
--continuous-batching \ # Enable concurrent request handling
--enable-prefix-cache \ # Reuse KV states for repeated prompts
--use-paged-cache \ # Block-based KV cache with dedup
--kv-cache-quantization q8 \ # Quantize cache: q4 or q8
--enable-disk-cache \ # Persist cache to SSD
--enable-jit \ # JIT Metal kernel compilation
--tool-call-parser auto \ # Auto-detect tool call format
--reasoning-parser auto \ # Auto-detect thinking format
--log-level INFO \ # Logging: DEBUG, INFO, WARNING, ERROR
--max-model-len 8192 \ # Max context length
--speculative-model <model> \ # Draft model for speculative decoding
--enable-pld \ # Prompt Lookup Decoding — no draft model, best for code/JSON/schemas
--distributed \ # Enable multi-Mac pipeline parallelism
--cluster-secret <secret> \ # Shared auth secret for workers
--distributed-mode pipeline \ # pipeline (default) or tensor (coming soon)
--worker-nodes ip:port,... \ # Manual worker IPs (overrides auto-discovery)
--cors-origins "*" # CORS allowed originsQuantization Options
vmlx convert <model> \
--bits 4 \ # Uniform quantization bits: 2, 3, 4, 6, 8
--group-size 64 \ # Quantization group size (default: 64)
--output ./output-dir \ # Output directory
--jang-profile JANG_3M \ # JANG mixed-precision profile
--calibration-method activations # Activation-aware calibrationImage Generation & Editing Options
```bash pip install vmlx[image]
Audio Options
TTS and STT require the mlx-audio package:
```bash pip install mlx-audio
Use with OpenAI SDK
from openai import OpenAI
client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
response = client.chat.completions.create(
model="local",
messages=[{"role": "user", "content": "Hello!"}],
stream=True,
)
for chunk in response:
print(chunk.choices[0].delta.content or "", end="", flush=True)Use with Anthropic SDK
import anthropic
client = anthropic.Anthropic(base_url="http://localhost:8000/v1", api_key="not-needed")
message = client.messages.create(
model="local",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello!"}],
)
print(message.content[0].text)Generation API
curl http://localhost:8000/v1/images/generations \
-H "Content-Type: application/json" \
-d '{
"model": "schnell",
"prompt": "A cat astronaut floating in space with Earth in the background",
"size": "1024x1024",
"n": 1
}'```python
Python (OpenAI SDK)
response = client.images.generate( model="schnell", prompt="A cat astronaut floating in space", size="1024x1024", n=1, ) ```
Editing API
```bash
API Reference
API Gateway
The desktop app runs an API Gateway on a single port (default 8080) that routes requests to all loaded models by name. Run multiple models simultaneously and access them all through one URL.
```bash
Works with Ollama CLI too
OLLAMA_HOST=http://localhost:8080 ollama run Qwen3.5-122B ```
The gateway supports OpenAI, Anthropic, and Ollama wire formats. Configure the port in the API tab.
Endpoints
OpenAI / Anthropic
| Method | Path | Description |
|---|---|---|
POST | /v1/chat/completions | OpenAI Chat Completions API (streaming + non-streaming) |
POST | /v1/messages | Anthropic Messages API |
POST | /v1/responses | OpenAI Responses API |
POST | /v1/completions | Text completions |
POST | /v1/images/generations | Image generation |
POST | /v1/images/edits | Image editing (Qwen Image Edit) |
POST | /v1/embeddings | Text embeddings |
POST | /v1/rerank | Document reranking |
POST | /v1/audio/transcriptions | Speech-to-text (Whisper) |
POST | /v1/audio/speech | Text-to-speech (Kokoro) |
GET | /v1/models | List loaded models |
GET | /v1/cache/stats | Cache statistics |
GET | /health | Server health check |
Ollama
| Method | Path | Description |
|---|---|---|
POST | /api/chat | Chat completion (NDJSON streaming) |
POST | /api/generate | Text generation (NDJSON streaming) |
GET | /api/tags | List loaded models |
POST | /api/show | Model details |
POST | /api/embeddings | Generate embeddings |
CLI Commands
vmlx serve <model> # Start inference server
vmlx convert <model> --bits 4 # MLX uniform quantization
vmlx convert <model> -j JANG_3M # JANG adaptive quantization
vmlx info <model> # Model metadata and config
vmlx doctor <model> # Run diagnostics
vmlx bench <model> # Performance benchmarks
vmlx-worker --secret <secret> # Start distributed worker node---
이미지 편집 API
curl http://localhost:8000/v1/images/edits \ -H "Content-Type: application/json" \ -d '{ "model": "qwen-image-edit", "prompt": "배경을 해질녘으로 변경", "image": "<base64 인코딩된 이미지>", "size": "1024x1024", "strength": 0.8 }' ```
创新的KV缓存压缩方案,解决MLX推理的显存瓶颈。持久化缓存设计独特,代码活跃,生产应用价值高。
- 需要让 Claude / Cursor 操作本地工具的 AI 工程师
- 构建多智能体协作系统的 Agent 开发者
- 构建企业知识库 / RAG 检索应用的团队
- 跨境业务、多语言内容运营团队
- 做语音类 AI 产品的开发者
- 配置 MCP 服务器时建议使用 stdio 传输 + JSON-RPC,避免暴露公网
- 本地部署优先选 GGUF 量化模型,节省显存并保持响应速度
- Agent 任务先做 dry-run 验证工具调用链,再开启自主执行
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- MCP 配置路径拼错或权限不足,重启 Claude Desktop 才生效
- 显存不足直接 OOM — 优先降低 context 或换更小的量化模型
- Python 依赖冲突:建议用 venv / uv 隔离环境
- CLI:直接 npm install -g / pip install,命令行调用
- 本地部署:CPU 8GB 起,GPU 推荐 16GB+ 显存
- 云端托管:可放在 Vercel / Railway / Fly.io 等 PaaS 平台
- 开源免费,支持本地部署,数据完全自主可控
- 活跃的 GitHub 开源社区,持续迭代更新
- 提供详细文档和使用示例,新手友好
- 支持自定义配置,灵活适配不同使用环境
- 可作为基础组件集成进现有技术栈或进行二次开发
- 需要让 Claude / Cursor 操作本地工具的 AI 工程师
- 构建多智能体协作系统的 Agent 开发者
- 构建企业知识库 / RAG 检索应用的团队
- 跨境业务、多语言内容运营团队
- 配置 MCP 服务器时建议使用 stdio 传输 + JSON-RPC,避免暴露公网
- 本地部署优先选 GGUF 量化模型,节省显存并保持响应速度
- Agent 任务先做 dry-run 验证工具调用链,再开启自主执行
- API key 直接提交到 git 仓库(请用 .env 并加入 .gitignore)
- MCP 配置路径拼错或权限不足,重启 Claude Desktop 才生效
- 显存不足直接 OOM — 优先降低 context 或换更小的量化模型
- Python 依赖冲突:建议用 venv / uv 隔离环境
- 本地部署运行,保护数据隐私,满足合规要求
- 自定义集成到现有系统,扩展技术栈能力
- 作为开源基础组件进行商业化二次开发
- +Apache-2.0 协议,可免费商用
- +完全开源免费,无授权费用
- +本地部署,数据完全自主可控
- +开发者社区支持,遇问题可查可问
- −安装和初始配置可能需要一定技术基础
- −功能完整性通常不如成熟商业产品
- −技术支持主要依赖开源社区,响应速度不稳定
AI Skill Hub 为第三方内容聚合平台,本页面信息基于公开数据整理,不对工具功能和质量作任何法律背书。
建议在沙箱或测试环境中充分验证后,再部署至生产环境,并做好必要的安全评估。
✅ Apache 2.0 — 宽松开源协议,可商用,需保留版权声明和 NOTICE 文件,含专利授权条款。
AI Skill Hub 点评:vmlx MCP工具 的核心功能完整,质量优秀。对于AI 技术爱好者来说,这是一个值得纳入个人工具库的选择。建议先在非生产环境试用,再逐步推广。
| 原始名称 | vmlx |
| 原始描述 | 开源MCP工具:vMLX - JANGTQ Uber Compressed MLX Models - L2 Disk Cache (survives restart) + L1。⭐512 · Python |
| Topics | 模型压缩KV缓存优化MLX框架MCP工具显存优化 |
| GitHub | https://github.com/jjang-ai/vmlx |
| License | Apache-2.0 |
| 语言 | Python |
收录时间:2026-05-18 · 更新时间:2026-05-19 · License:Apache-2.0 · AI Skill Hub 不对第三方内容的准确性作法律背书。